

For any technology to be successful, it needs to move from the early adopter market segment to the majority, i.e., crossing the chasm. Till now Machine Learning has been primarily in the hype phase and the early adopters and innovators have mostly driven adoption. In the next few years, ML (and in general AI) can move from the hype phase to the correction phase (Figure 1) if the focus is kept on user adoption and value creation.
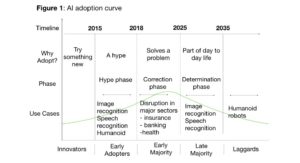
However, to move to the majority phase — some significant product development challenges need to be overcome.
Challenges to Overcome
High Development Cost
The salaries of data scientists are exuberantly high, for example, a data scientist in Bangalore can earn somewhere around Rs 20,00,000 per year and up. However, challenges with product development that cannot be solved by a single person; e.g., data gathering and preparation.
For machine learning to be widely used and adopted by a wide range of mission-driven organisations, the cost of development has to come down. To achieve that, we can take ideas from two areas: open source development and decentralised product development.
With today’s technological advancement and online tools, anyone can access talent anywhere. For example, a few months ago I have started working on a machine learning project to improve roof-top solar adoption, where we are using decentralised, and open source product development approaches.
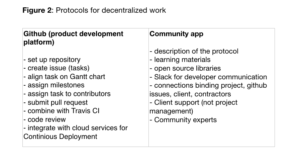
What we are following is a hybrid model of open source and traditional software development (closed team). A community of data scientist and data engineers are selected, tasks with bounties announced to the community, and people from the community can take up the jobs. The code is open sourced, and the open source protocols are being followed. For example, for the solar project, we have around 40 highly engaged junior ML engineers from all over India contributing and developing the product. Tasks announced in the community and students can take up those tasks, and start working on them under the supervision of an expert. Below the screenshot of the task assignment in slack.
However, just giving task is not enough. Processes need to be kept in place to enforce that the quality of the code and product deliverables. To achieve so, we are following a product development protocol (figure 2).
Using the above approach we have seen that a factor of three has reduced the product development cost.
Intellectual Property Concerns
One of the concerns about open source projects is IP (Intellectual Property) — how to protect the IP if the team is decentralised and somewhat open. A few years ago it would have been a valid argument as IP driven by ownership of code, but in the era of Machine Learning, ownership of data driving the IP. So as long as one has the data, the IP is protected.
In this way, the data is kept within a small community and yet leveraging the strengths of an open source development.
 Data and Trust
Data and Trust
A community behind a product can give access to a large amount of data. The wisdom of the crowd, fueling diversity through people from different backgrounds and locations, can result in innovative approaches to gather and work with the data. For specific projects, members can even bring in their data through, e.g., images, music, movie recommendations, text and so on. For the solar project mentioned above, we are also using a community-driven approach to gather data. The engineers are creating tagged data for their given task, thus giving access to a large amount of tagged data.
Figure 3. Masked images generated by the community.

A community can also help to build trust. Companies that emerge from communities share common values, beliefs, and often a bigger vision that serves the long-term interests of those communities. Though, intrinsic motivation can play a more important role than in traditional company settings.
“The company’s interests are for the short term. The community’s interests are for the long term.” — Seth Godin
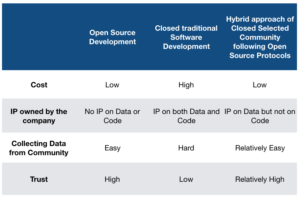
Table 1 summarises the three approaches of development
I firmly believe that the future of AI and Machine Learning will not be driven by the ‘elites’ but by the community through grass root movement. We need a global community across countries, different ingraining values, and perspectives, to build great products that augment us and solve pressuring problems in today’s and tomorrow’s world. The development of the solar project is a classic example of a grass root movement. We are working with students from all over India, who are contributing to building the machine learning models. Most of the code is open sourced, and we regularly add more contributors to the project. The community of enthusiasts is generating Even the data. I believe this is the direction that future development of intelligent products should follow.
In the next post, I will show some more results and outputs from work done in the community-driven solar project.
Rudradeb recently published a book titled ‘Creating Value with Artificial Intelligence.’ The Kindle version of the book is available on Amazon(India). Connect with him via LinkedIn if you want to get a free copy of the book.




